
Viele Teams erwarten beim Einsatz von AI im Support sinkende Kosten. In den ersten Wochen stimmt das oft. Dann kommt der zweite Monat, und die Rechnung liegt weit über dem Budget. Das liegt selten am Prompting, sondern fast immer an der Architektur.
Die Falle der unbegrenzten Skalierung
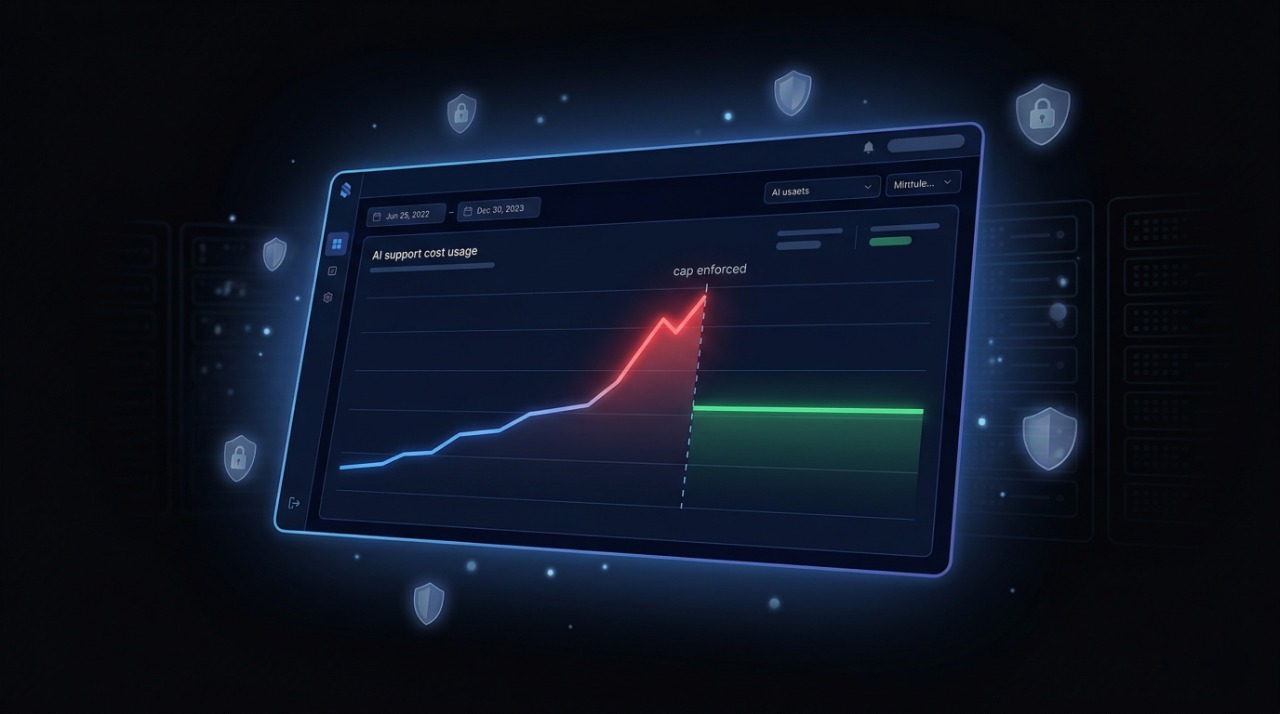
Ein Sprachmodell kann tausend Gespräche gleichzeitig führen, aber jede Nachricht kostet: Klassifizierung, Retrieval, Antwortsynthese und Provider-Aufrufe. Ohne Leitplanken wächst Nutzung unsichtbar.
Bei Produktionsvolumen werden kleine Kosten pro Nachricht schnell zu einer echten operativen Ausgabe.
Unbegrenzte Skalierung ist kein Feature. Sie ist ein Risiko, das einen Schalter braucht.
Warum normale Rate Limits nicht reichen
Provider-Rate-Limits schützen vor allem die Provider-Infrastruktur. Sie begrenzen meist Requests pro Minute, nicht monatliche Ausgaben pro Bot, Workspace oder Use Case.
Die Lösung ist Budgetkontrolle auf Bot-Ebene. Jeder Assistent braucht ein eigenes Monatslimit, Alert-Schwellen und ein kontrolliertes Fallback-Verhalten.
Kontrollen, die funktionieren
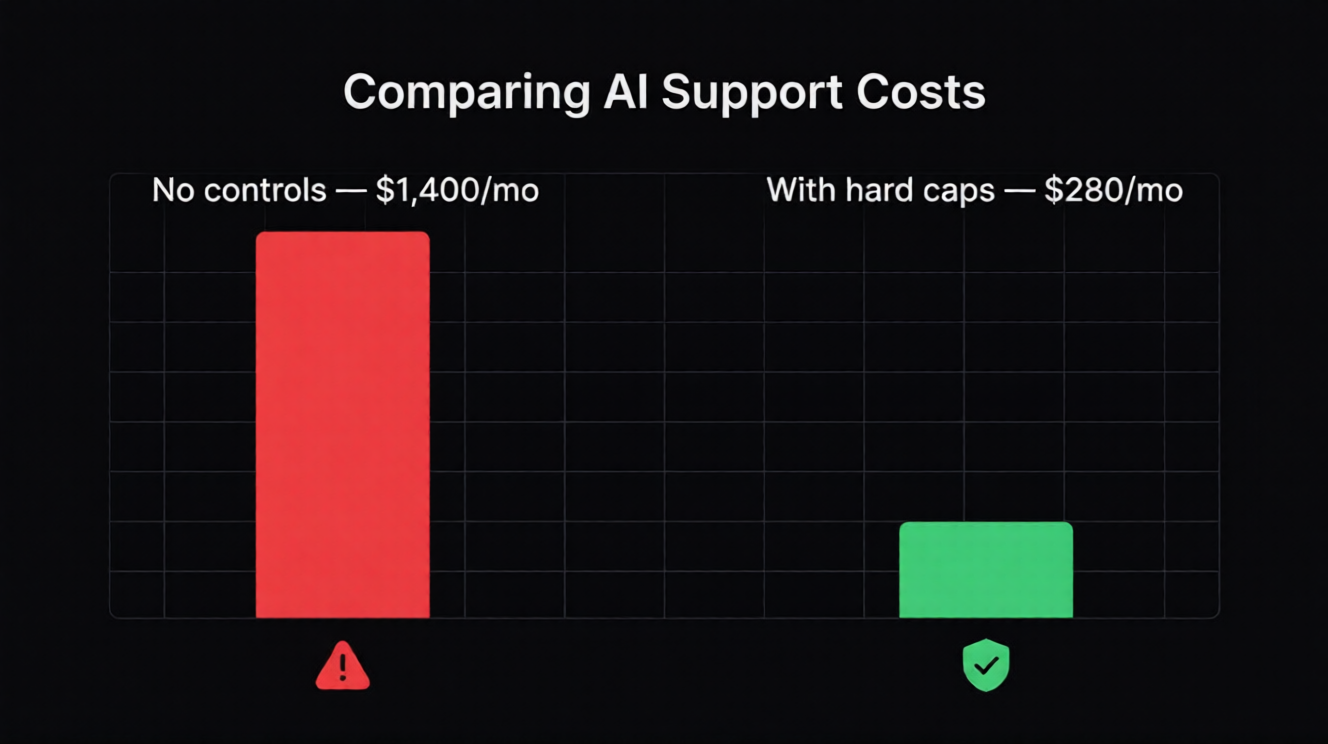
Harter Monatsstopp. Der Bot kann nicht mehr ausgeben als das definierte Limit und wechselt danach in einen sicheren Fallback.
Limits pro Domain und API-Key. Ein einzelnes Widget, ein Kunde oder eine Integration kann nicht das ganze Workspace-Budget verbrauchen.
Alert-Webhooks. Teams sollten bei 70%, 90% und 100% Budgetauslastung informiert werden, bevor Finance das Problem findet.
Model Routing senkt die Basis
Nicht jede Anfrage braucht das teuerste Modell. FAQ, Statusfragen und kurze Bestätigungen können auf günstigeren Modellen laufen, während komplexe Logik und sensible Eskalationen stärkere Modelle nutzen.
Startpunkt
Definieren Sie vor dem Launch ein akzeptables Monatsbudget pro Bot. Setzen Sie ein hartes Limit darunter, fügen Sie Alerts hinzu und routen Sie risikoarme Intents zu kleineren Modellen.
Möchten Sie AI Support einführen?
Starten Sie Ihren kostenlosen Specteron-Test und sehen Sie sich den Unterschied direkt an.
Jetzt starten